Especially when it comes to Bug Bounty hunting, reconnaissance is one of the most valuable things to do. There are still "easy wins“ out there which can be found, if you have a good strategy when it comes to reconnaissance. Bounty hunters like @NahamSec, @Th3g3nt3lman and @TomNomNom are showing this regularly and I can only recommend to follow them and use their tools.
In this Blogpost I want to explain, how I am normally performing reconnaissance during Pentests and for Bug Bounties.
Who we are
We are a team of security enthusiasts based in Austria that want to make the Internet a better and safer place. Offensity helps professional IT admins identify vulnerabilities by scanning their infrastructure and uses a lot of the techniques described here. Make sure to test our tool - it's completely free for up to 2 domains and 50 subdomains!
Go ahead! Get free security reports for your company's domain!
You will need to verify that you are the owner of the domain you want to scan, though. It's not a penetration testing tool ;)
An Overview
The biggest challenge is: WHERE SHOULD I START?!
Well, you need a plan. The following illustration (click to enlarge) might look a bit confusing, but I try to explain a lot of the steps in this post:
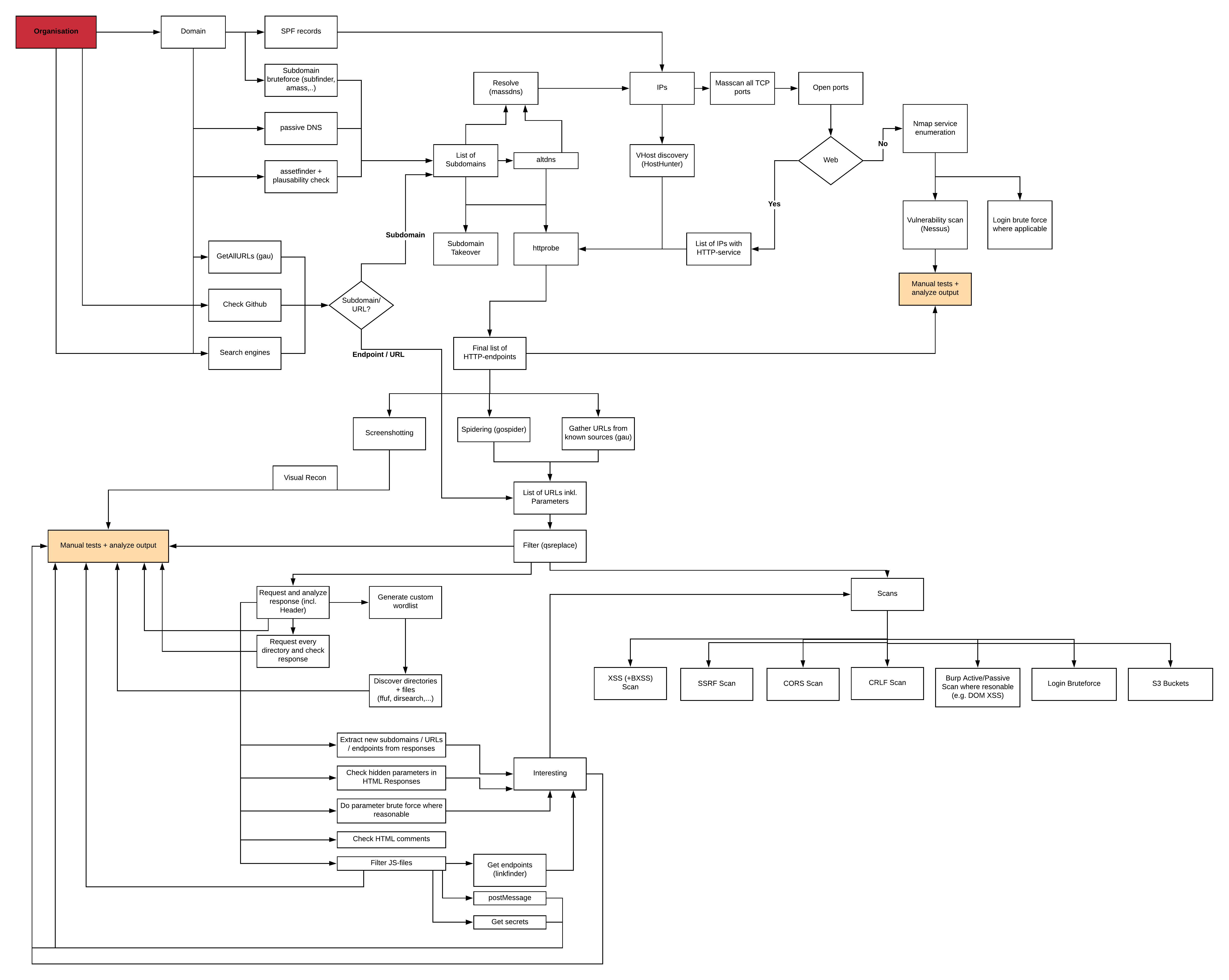
Basically, we want to identify as many endpoints as possible, sort and filter them, scan them automatically and perform manual assessments where applicable - easy right?
We need to identify assets which belong to the target company and are in-scope. The first thing is to identify domains and sub-domains belonging to the target.
Subdomain Enumeration
Subfinder
Subfinder is a subdomain discovery tool that discovers valid subdomains for websites. Designed as a passive framework to be useful for bug bounties and safe for penetration testing.
GitHub Link
# Install
go get github.com/subfinder/subfinder
# Basic usage
subfinder -d example.com > example.com.subs
# Recursive
subfinder -d example.com -recursive -silent -t 200 -o example.com.subs
# Use censys for even more results
subfinder -d example.com -b -w wordlist.txt -t 100 -sources censys -set-settings CensysPages=2 -v -o example.com.subsamass
In-depth Attack Surface Mapping and Asset Discovery https://owasp.org/www-project-amass/
Installation instructions can be found here.
# passive
amass enum --passive -d example.com -o example.com.subs
# active
amass enum -src -ip -brute -min-for-recursive 2 -d example.com -o example.com.subsUse certificate transparency logs
crt.sh provides a PostgreSQL interface to their data. The script below extracts sub-domains for a given domain name using crt.sh PostgreSQL Interface
GitHub Link
Get alerted if a new subdomain appears on the target (using a Slack Bot)
Sublert is a security and reconnaissance tool which leverages certificate transparency to automatically monitor new subdomains deployed by specific organizations and issued TLS/SSL certificate. Technical details here: here
GitHub Link
assetfinder
Find domains and subdomains related to a given domain
GitHub Link
# Install
go get -u github.com/tomnomnom/assetfinder
# Basic usage
assetfinder [--subs-only] <domain>GetAllUrls (gau) for Subdomain-Enumeration
Fetch known URLs from AlienVault's Open Threat Exchange, the Wayback Machine, and Common Crawl.
Github Link
# Install
GO111MODULE=on go get -u -v github.com/lc/gau
# Extract subdomains from output
gau -subs example.com | cut -d / -f 3 | sort -uSearch Engines
Use Github search and other search engines
The tool subfinder (look above) already provides the possibility to use search engines for subdomain enumeration, but it does not support GitHub.
Make sure you check Github - type in the Domain of the company and manually look through the code-results. Interesting endpoints and probably secrets that shouldn't be there can be found!
Github Recon
GitHub is a Goldmine - @Th3g3nt3lman mastered it to find secrets on GitHub. I can only recommend to watch his Video together with @Nahamsec where he shares some insights.
Be creative when it comes to keywords and use their search! Check their GitHub company profile, filter for languages and start searching:
org:example.com hmac
Within the results check the Repositories, Code, Commits and Issues. Code is the biggest one where you will probably find the most. Issues is a goldmine - Developers tend to share too much information there ;)
Some things you can search for:
- “company.com” “dev”
- “dev.company.com”
- “company.com” API_key
- “company.com” password
- “api.company.com” authorization
Additionally, here are some tools (won't go into detail here) which I use regularly:
- https://github.com/techgaun/github-dorks
- https://github.com/michenriksen/gitrob
- https://github.com/eth0izzle/shhgit
- https://github.com/anshumanbh/git-all-secrets
- https://github.com/hisxo/gitGraber
Google
Do not forget Google - it can be worth it! Some examples (taken from here):
- site:target.com -www
- site:target.com intitle:”test” -support
- site:target.com ext:php | ext:html
- site:subdomain.target.com
- site:target.com inurl:auth
- site:target.com inurl:dev
So, if you want to find WP-Config files with cleartext DB-credentials in it, just go ahead:
inurl:wp-config.php intext:DB_PASSWORD -stackoverflow -wpbeginner -foro -forum -topic -blog -about -docs -articles
Shodan
Do not forget to use other search engines such as Shodan. Some examples (taken from here):
- country: find devices in a particular country
- geo: you can pass it coordinates
- hostname: find values that match the hostname
- net: search based on an IP or /x CIDR
- os: search based on operating system
- port: find particular ports that are open
- before/after: find results within a timeframe
Shodan also provides a facet interface, which can be very helpful if you want to get an overview about bigger network-ranges.

Censys
Censys can be compared with Shodan - have a look at it.
https://censys.io/

Get Subdomains from IPs
Hosthunter
HostHunter a recon tool for discovering hostnames using OSINT techniques.
GitHub Link (includes installation instructions)
# Basic usage
python3 hosthunter.py <target-ips.txt> > vhosts.txtAfter enumerating subdomains, we can try to find additional subdomains by generating permutations, alterations and mutations of known subdomains.
Altdns
Altdns is a DNS recon tool that allows for the discovery of subdomains that conform to patterns. Altdns takes in words that could be present in subdomains under a domain (such as test, dev, staging) as well as takes in a list of subdomains that you know of.
# Installation
pip install py-altdns
# Basic usage
altdns -i known-subdomains.txt -o raw-data_output -w words.txt -r -s results_output.txtDNSGen
Generates combination of domain names from the provided input.
GitHub Link
# Installation
pip3 install dnsgen
# Basic usage
dnsgen known-domains.txtWhen doing DNS permutations using various tools, not all of them check, if the outcome actually resolves to an IP-Address. The fastest way to resolve thousands of (sub)-domains is massdns.
massdns
A high-performance DNS stub resolver for bulk lookups and reconnaissance (subdomain enumeration)
GitHub Link
# Installation
git clone https://github.com/blechschmidt/massdns.git
cd massdns
make
# Basic usage
./bin/massdns -r lists/resolvers.txt -t A domains.txt > results.txt
#In combination with dnsgen
cat domains.txt | dnsgen -w words.txt -f - | massdns -r lists/resolvers.txt -t A -o S -w massdns.outNow you should have a fairly large list of subdomains and corresponding IPs. I will not go into detail on how you do a TCP or UDP portscan or how you conduct an automated vulnerability scan in this post.
An interesting fact for us as security researchers is, if the discovered subdomains have web-services running.
httprobe
Take a list of domains and probe for working HTTP and HTTPS servers
GitHub Link
# Install
go get -u github.com/tomnomnom/httprobe
# Basic usage
$ cat recon/example/domains.txt
example.com
example.edu
example.net
$ cat recon/example/domains.txt | httprobe
http://example.com
http://example.net
http://example.edu
https://example.com
https://example.edu
https://example.net
# Use other ports
cat domains.txt | httprobe -p http:81 -p https:8443
# Concurrency - You can set the concurrency level with the -c flag:
cat domains.txt | httprobe -c 50Additionally, we can check if any subdomain is vulnerable to subdomain takeover:
subjack
Subjack is a Subdomain Takeover tool written in Go designed to scan a list of subdomains concurrently and identify ones that can be hijacked.
# Install
go get github.com/haccer/subjack
# Basic usage
./subjack -w subdomains.txt -t 100 -timeout 30 -o results.txt -sslOther tools to scan for subdomain takeover vulnerabilities:
Screenshot all Websites for Visual Recon
After we compiled our list of HTTP enabled targets, we want to know, what webservices are running on these hosts. One of the first steps I perform is to actually have a look at the website. The easiest and fastest way to do this for a lot of targets is to perform automated screenshotting of all targets.
EyeWitness
EyeWitness is designed to take screenshots of websites provide some server header info, and identify default credentials (if known).
GitHub Link
# Install instructions can be found here https://github.com/FortyNorthSecurity/EyeWitness
# Basic usage
./EyeWitness.py -f filename --timeout optionaltimeout
# Further examples
./EyeWitness -f urls.txt --web
./EyeWitness -x urls.xml --timeout 8
./EyeWitness.py -f urls.txt --web --proxy-ip 127.0.0.1 --proxy-port 8080 --proxy-type socks5 --timeout 120webscreenshot
A simple script to screenshot a list of websites, based on the url-to-image PhantomJS script.
GitHub Link
# Clone
git clone https://github.com/maaaaz/webscreenshot.git
# Basic usage
python webscreenshot.py -i list.txt -w 40URL and Parameter Discovery
The easiest active way to discover URLs and corresponding parameters on the target is to crawl the site.
GoSpider
A fast web spider written in Go
GitHub Link
# Install
go get -u github.com/jaeles-project/gospider
# Basic usage
# Run with single site
gospider -s "https://google.com/" -o output -c 10 -d 1
# Run with site list
gospider -S sites.txt -o output -c 10 -d 1
# Also get URLs from 3rd party (Archive.org, CommonCrawl.org, VirusTotal.com, AlienVault.com) and include subdomains
gospider -s "https://google.com/" -o output -c 10 -d 1 --other-source --include-subs
# Blacklist url/file extension.
gospider -s "https://google.com/" -o output -c 10 -d 1 --blacklist ".(woff|pdf)"Arjun
Web applications use parameters (or queries) to accept user input. We want to find as many parameters as possible which we can later scan or review manually. That's where Arjun comes in:
GitHub Link
# Install
git clone https://github.com/s0md3v/Arjun.git
# Scanning a single URL
python3 arjun.py -u https://api.example.com/endpoint --get
python3 arjun.py -u https://api.example.com/endpoint --post
# Scanning multiple URLs
python3 arjun.py --urls targets.txt --get
# Multi-threading
python3 arjun.py -u https://api.example.com/endpoint --get -t 22GetAllUrls (gau)
We already covered gau above. GetAllUrls (gau) fetches known URLs from AlienVault's Open Threat Exchange, the Wayback Machine, and Common Crawl for any given domain. Inspired by Tomnomnom's waybackurls.
# Install
GO111MODULE=on go get -u -v github.com/lc/gau
# Basic usage
printf example.com | gau
cat domains.txt | gau
gau example.com
gau -subs example.comFiltering
After having assembled a huge list of subdomains, URLs, and parameters, we now want to filter them, and remove duplicates.
qsreplace
Removes duplicate URLs and parameter combinations
GitHub Link
# Install
go get -u github.com/tomnomnom/qsreplace
# Basic usage
~# cat urls.txt
https://www.example.com/test1?param1=1¶m2=2
https://www.example.com/test1?param2=1¶m1=2
https://www.example.com/test2?param2=1¶m1=2
https://www.example.com/test1?param3=1¶m4=2
# Remove duplicates
~# cat urls.txt |qsreplace -a
https://www.example.com/test1?param1=1¶m2=2
https://www.example.com/test2?param1=2¶m2=1
https://www.example.com/test1?param3=1¶m4=2We can use the following tool to find potentially interesting URLs
gf
A wrapper around grep to avoid typing common patterns. For example one can write the following gf template to grep for potential URLs that are vulnerable to open-redirects or SSRF
GitHub Link
~/.gf# cat redirect.json
{
"flags" : "-HanrE",
"pattern" : "url=|from_url=|load_url=|file_url=|page_url=|file_name=|page=|folder=|folder_url=|login_url=|img_url=|return_url=|return_to=|next=|redirect=|redirect_to=|logout=|checkout=|checko
~# cat urls-uniq.txt
https://www.example.com/test1?param1=1¶m2=2
https://www.example.com/test2?param1=2¶m2=1
https://www.example.com/test1?login_url=2¶m3=1
~# gf redirect urls-uniq.txt
urls-uniq.txt:3:https://www.example.com/test1?login_url=2¶m3=1Some more ideas on gf patterns can be found here, including patterns for interesting subdomains, SSRF and more:
https://github.com/1ndianl33t/Gf-Patterns
Use BurpSuite's passive scans
It makes total sense to "import" as many URLs as possible into BurpSuite. How to "import"? Here is how I do it:
cat urls.txt | parallel -j50 -q curl -x http://127.0.0.1:8080 -w 'Status:%{http_code}\t Size:%{size_download}\t %{url_effective}\n' -o /dev/null -skBurpSuite automatically performs passive checks on the way (e.g. DOM-Based-XSS).
Use extensions like Secret Finder to find secrets in responses (e.g. API keys).
Use AWS Security Checks to find AWS Bucket security issues.
There a tons of useful extensions which to (semi) passive checks - have a look in the BApp-Store!
Discover even more content
Find all js files
JavaScipt files are always worth to have a look at. I always filter for URLs returning JavaScript files and I save them in an extra file for later.
A great write-up about static JavaScript analysis can be found here:
Static Analysis of Client-Side JavaScript for pen testers and bug bounty hunters
cat urls.txt | grep "\.js" > js-urls.txt
# check, if they are actually available
cat js-urls.txt | parallel -j50 -q curl -w 'Status:%{http_code}\t Size:%{size_download}\t %{url_effective}\n' -o /dev/null -sk | grep Status:200Linkfinder
A python script that finds endpoints in JavaScript files
GitHub Link
# Install
git clone https://github.com/GerbenJavado/LinkFinder.git
cd LinkFinder
python setup.py install
pip3 install -r requirements.txt
# Basic usage
# Get HTML report
python linkfinder.py -i https://example.com/1.js -o results.html
# Output to CLI
python linkfinder.py -i https://example.com/1.js -o cliAs explained before, there are BurpSuite Plugins checking for secrets in HTTP responses.
There are also other tools available to discover potential secrets in various files (again, check all JS files!):
- https://github.com/securing/DumpsterDiver
- https://github.com/auth0/repo-supervisor#repo-supervisor
- https://github.com/dxa4481/truffleHog
Find hidden directories or files
ffuf
Fast web fuzzer written in Go
GitHub Link
# Installation
go get github.com/ffuf/ffuf
# Basic usage
ffuf -w wordlist.txt -u https://example.com/FUZZ
# Automatically calibrate filtering options
ffuf -w wordlist.txt -u https://example.com/FUZZ -ac
# Fuzz file paths from wordlist.txt, match all responses but filter out those with content-size 42
ffuf -w wordlist.txt -u https://example.org/FUZZ -mc all -fs 42 -c -vFor Web fuzzing, you need good wordlists. You can use default wordlists, provided by DirBuster, or special wordlists from the SecLists repository. You should also use a custom wordlist which fits the current target. You can use CeWL for that:
CeWL
CeWL is a Custom Word List Generator
GitHub Link
~ cewl -d 2 -m 5 -w docswords.txt https://example.com
~ wc -l docswords.txt
13 docswords.txtFinal Thoughts
This is just the way I do it and I tried to cover most of my default procedure here in this post. I will try to update this every now and then - there are tons of great tools out there which make our lives easier.
In my opinion, good recon is essential. You have to find things that nobody else found before in order to find those critical bugs. Make sure you have a plan and document everything you found, you will probably need it later.
If you have questions or suggestions, just drop me an E-Mail
Make sure to follow @Offensity on Twitter for future updates!
Further Resources and Tools
- A Broken-URL Checker
https://github.com/tomnomnom/burl - Fetch many paths for many hosts - without killing the hosts
- Make concurrent requests with the curl command-line tool
https://github.com/tomnomnom/concurl - Extract endpoints from APK files
https://github.com/ndelphit/apkurlgrep - Quick XSS Scanner
https://github.com/tomnomnom/hacks/tree/master/kxss - DalFox(Finder Of XSS) / Parameter Analysis and XSS Scanning tool based on golang
https://github.com/hahwul/dalfox - shuffleDNS is a wrapper around massdns written in go that allows you to enumerate valid subdomains using active bruteforce as well as resolve subdomains with wildcard handling and easy input-output support.
https://github.com/projectdiscovery/shuffledns - Web path scanner
https://github.com/maurosoria/dirsearch - Directory/File, DNS and VHost busting tool written in Go
https://github.com/OJ/gobuster - Web application fuzzer
https://github.com/xmendez/wfuzz/ - dns recon & research, find & lookup dns records
https://dnsdumpster.com/ - Fast subdomains enumeration tool for penetration testers
https://github.com/aboul3la/Sublist3r - Knock Subdomain Scan
https://github.com/guelfoweb/knock - A Python script to parse net blocks & domain names from SPF record
https://github.com/0xbharath/assets-from-spf/ - A tool to fastly get all javascript sources/files
https://github.com/003random/getJS - Offering researchers and community members open access to data from Project Sonar, which conducts internet-wide surveys to gain insights into global exposure to common vulnerabilities
https://opendata.rapid7.com/ - https://github.com/danielmiessler/SecLists